首页
关于
论坛
投稿
搜索
机器学习
2022-05-09
2 / 3
机器学习
xgboost: 速度快效果好的boosting模型
何通
/
2015-03-04
在数据分析的过程中,我们经常需要对数据建模并做预测。在众多的选择中,randomForest, gbm和glmnet是三个尤其流行的R包,它们在Kaggle的各大数据挖掘竞赛中的出现频率独占鳌头,被坊间人称为R数据挖掘包中的三驾马车。根据我的个人经验,gbm包比同样是使用树模型的randomForest包占用的内存更少,同时训练速度较快,尤其受到大家的喜爱。在python的机器学习库sklearn……
机器学习
COS每周精选:算法学习知哪些?
谢益辉 / 王威廉 / 冷静 / 王小宁
/
2015-01-19
本期投稿:谢益辉 王威廉 冷静 王小宁 […] K-means是最常用的聚类算法之一:容易理解,实现不难,虽然会有local optimum,但通常结果也不差。但k-means也不是万金油,比如在一些比较复杂的问题和非线性数据分布上,k-means也会失败。普林斯顿博士David Robinson写了一篇不错的分析文章,介绍了几种k-means会失效的情形。 基于遗传算法的小车模拟,……
机器学习
COS每周精选:深度学习面面观
王威廉 / 王小宁
/
2014-12-07
本期投稿:王威廉 王小宁 在了解深度学习之前,让我们先来看看@戴文渊 大牛的关于机器学习的前世今生的介绍。 斯坦福深度学习博士Richard Socher貌似并未直接赶赴普林斯顿大学担任教职,而是在硅谷进行深度学习创业,目前得到800万美金的资金支持。据其介绍,其网站能通过点鼠标以及托、拉、提、拽的操作进行深度学习模型训练。DEMO,Wired. 美国波士顿大学以及东北大学的物理系教授写了一篇新……
机器学习
COS每周精选:机器学习哪家强?
冷静 / 蔡占锐 / 王小宁
/
2014-11-16
本期投稿: 冷静 蔡占锐 王小宁 […] 很多人在学习机器学习,但是这里面也有误区,你知道么?机器学习的资料也不断的出现,到底有哪些机器学习中深度学习的资料供我们学习,小编搜罗了一下,供大家参考。许多同学对于机器学习及深度学习的困惑在于,数学方面已经大致理解了,但是动起手来却不知道如何下手写代码。斯坦福深度学习博士Andrej Karpathy写了一篇实战版本的深度学习及机器学习教……
推荐文章
“支持向量机系列”的番外篇二: Kernel II
张驰原
/
2014-05-08
原文链接请点击这里 在之前我们介绍了如何用 Kernel 方法来将线性 SVM 进行推广以使其能够处理非线性的情况,那里用到的方法就是通过一个非线性映射 $\phi(\cdot)$将原始数据进行映射,使得原来的非线性问题在映射之后的空间中变成线性的问题。然后我们利用核函数来简化计算,使得这样的方法在实际中变得可行。不过,从线性到非线性的推广我们并没有把 SVM 的式子从头推导一遍,而只是直接把最终……
推荐文章
“支持向量机系列”的番外篇一: Duality
张驰原
/
2014-03-19
原文链接请点击这里 在之前关于support vector的推导中,我们提到了dual,这里再来补充一点相关的知识。这套理论不仅适用于 SVM 的优化问题,而是对于所有带约束的优化问题都适用的,是优化理论中的一个重要部分。简单来说,对于任意一个带约束的优化都可以写成这样的形式: $$ \begin{aligned} \min&f_0(x) \\ s.t. &f_i(x)\leq……
推荐文章
支持向量机系列五:Numerical Optimization
张驰原
/
2014-03-06
原文链接请点击这里 作为支持向量机系列的基本篇的最后一篇文章,我在这里打算简单地介绍一下用于优化 dual 问题的 Sequential Minimal Optimization (SMO) 方法。确确实实只是简单介绍一下,原因主要有两个:第一这类优化算法,特别是牵涉到实现细节的时候,干巴巴地讲算法不太好玩,有时候讲出来每个人实现得结果还不一样,提一下方法,再结合实际的实现代码的话,应该会更加明……
推荐文章
支持向量机系列四:Outliers
张驰原
/
2014-02-22
原文链接请点击这里 在最开始讨论支持向量机的时候,我们就假定,数据是线性可分的,亦即我们可以找到一个可行的超平面将数据完全分开。后来为了处理非线性数据,使用 Kernel 方法对原来的线性 SVM 进行了推广,使得非线性的的情况也能处理。虽然通过映射\(\phi(\cdot)\)将原始数据映射到高维空间之后,能够线性分隔的概率大大增加,但是对于某些情况还是很难处理。例如可能并不是因为数据本身是非线……
推荐文章
支持向量机系列三:Kernel
张驰原
/
2014-02-17
原文链接请点击这里 前面我们介绍了线性情况下的支持向量机,它通过寻找一个线性的超平面来达到对数据进行分类的目的。不过,由于是线性方法,所以对非线性的数据就没有办法处理了。例如图中的两类数据,分别分布为两个圆圈的形状,不论是任何高级的分类器,只要它是线性的,就没法处理,SVM 也不行。因为这样的数据本身就是线性不可分的。 对于这个数据集,我可以悄悄透露一下:我生成它的时候就是用两个半径不同的圆圈加上……
推荐文章
支持向量机系列二: Support Vector
张驰原
/
2014-01-25
原文链接请点击这里 上一次介绍支持向量机,结果说到 Maximum Margin Classifier ,到最后都没有说“支持向量”到底是什么东西。不妨回忆一下上次最后一张图: 可以看到两个支撑着中间的 gap 的超平面,它们到中间的 separating hyper plane 的距离相等(想想看:为什么一定是相等的?),即我们所能得到的最大的 geometrical margin……
推荐文章
支持向量机系列一: Maximum Margin Classifier
张驰原
/
2014-01-23
原文链接请点击这里 支持向量机即 Support Vector Machine,简称 SVM 。我最开始听说这头机器的名号的时候,一种神秘感就油然而生,似乎把 Support 这么一个具体的动作和 Vector 这么一个抽象的概念拼到一起,然后再做成一个 Machine ,一听就很玄了! 不过后来我才知道,原来 SVM 它并不是一头机器,而是一种算法,或者,确切地说,是一类算法,当然,这样抠字眼的……
统计应用
LDA-math-LDA 文本建模
靳志辉
/
2013-03-07
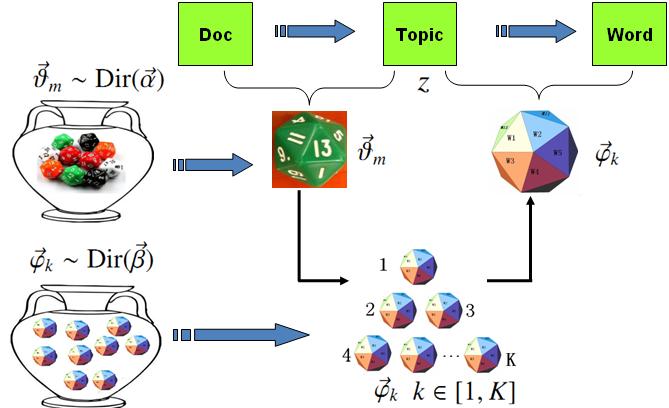
对于上述的 PLSA 模型,贝叶斯学派显然是有意见的,doc-topic 骰子$\overrightarrow{\theta}_m$和 topic-word 骰子$\overrightarrow{\varphi}_k$都是模型中的参数,参数都是随机变量,怎么能没有先验分布呢?于是,类似于对 Unigram Model 的贝叶斯改造, 我们也可以如下在两个骰子参数前加上先验分布从而把 PLSA 对应……
««
«
1
2
3
»
»»